Este artículo está dirigido a quienes necesitan hacerse una idea general sobre Big Data para poder introducirlo en sus organizaciones o para entender una parte de los elementos de la Transformación Digital.
Los datos están en todas partes. De hecho, la cantidad de datos digitales que existe está creciendo a un ritmo acelerado; existen más de 2.7 zettabytes [i]. de datos en el universo digital de hoy en día, y se proyecta que crecerá a 180 zettabytes en 2025. [1]
Toda esta información, desde sus fotos hasta las finanzas de las grandes empresas, han comenzado a analizarse recientemente para extraer ideas que pueden ayudar a las organizaciones a mejorar sus negocios. Este mecanismo para procesar grandes cantidades y diversos tipos de datos se conoce como Big Data.
Definición
Big Data se refiere a grandes conjuntos de datos complejos, tanto estructurados (bases de datos y archivos con registros con registros con formatos predefinidos) como no estructurados (textos, mail, planillas de cálculo, sonidos, los, videos, fotos), que las técnicas de procesamiento y / o algoritmos tradicionales no pueden procesar. Su objetivo es revelar patrones ocultos –información relevante– y ha llevado a una evolución desde un paradigma impulsado por modelos a uno determinado por los datos [2]. Se basa Big Data en la interacción de:
- Tecnología: Maximiza la potencia de cálculo y la precisión algorítmica para reunir, analizar, vincular y comparar grandes conjuntos de datos.
- Análisis: Se basa en grandes conjuntos de datos para identificar patrones con el fin de encontrar información significativo sobre asuntos económicos, sociales, técnicos y legales.
- Mitología: La creencia generalizada de que los grandes conjuntos de datos ofrecen una forma superior de inteligencia y conocimiento que puede generar ideas que anteriormente eran imposibles, con el aura de la verdad, la objetividad y la precisión.
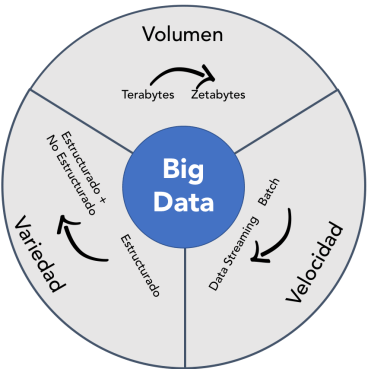
Big data puede describirse por las siguientes características[3] :
- Volumen: Es la cantidad de datos generados y almacenados. El tamaño –cantidad– de los datos determina el valor y la perspectiva potencial, y si realmente se puede considerar como Big Data o no.
- Variedad, El tipo y la naturaleza de los datos. Se produce porque los datos recopilados no pertenecen a una categoría específica ni a una fuente única, porque existen numerosos formatos de datos en bruto, obtenidos de la web, textos, video, sonido, imágenes, sensores, correos electrónicos, aplicaciones, sistemas de información, etc. y pueden estar estructurados o no estructurados.
- Velocidad, En el contexto de Big Data se refiere a la velocidad (TB/seg) a la que se generan y procesan los datos para satisfacer las demandas y los desafíos que requieren las empresas para su crecimiento y desarrollo.
Big Data no necesariamente deben satisfacer los requerimientos ACID (Atomicity, Consistency, Isolation, Durability) a diferencia de las bases de datos relacionales que es obligatorio que los satisfagan [4].
Modelo Base de Datos para Big Data
Al evaluar los fundamentos de por qué varias organizaciones están gravitando hacia el análisis de Big Data, es necesaria una comprensión concreta de los análisis tradicionales. Los métodos analíticos tradicionales incluyen conjuntos de datos estructurados que se consultan periódicamente para fines específicos. Un modelo de datos común utilizado para gestionar y procesar aplicaciones comerciales es el modelo relacional; este sistema de administración de bases de datos relacionales (RDBMS) proporciona «lenguajes de consulta fáciles de usar» y tiene una simplicidad que otros modelos jerárquicos o de red no pueden ofrecer. Dentro de este sistema hay tablas, cada una con un nombre único, donde los datos relacionados se almacenan en filas y columnas.
Para el caso de grandes volúmenes de datos (sobre los Terabytes) en entornos distribuidos (los datos almacenados en varios servidores) existe un paradigma de programación llamado MapReduce. Éste cuenta con dos funciones fundamentales: la función Map y la Reduce.
La función Map ejecuta la clasificación (sort) y filtrado, técnicamente se representa como se muestra en la figura siguiente. Map toma un documento como entrada, divide las palabras contenidas en un documento (es decir, un archivo de texto) y crea un par (Key, Value) para cada palabra en el documento.
Map toma un documento como entrada, divide las palabras contenidas en un documento (es decir, un archivo de texto) y crea un par (Key, Value) para cada palabra en el documento.
Por su parte la función Reduce toma el resultado de la función Map como entrada, luego completa operaciones de agrupación y agregación para combinar esos conjuntos de datos en conjuntos más pequeños de tuplas. Su representación se muestra a continuación.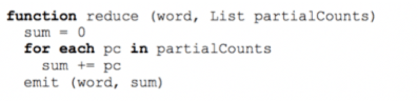
En resumen, Reduce toma la lista que genera Map y cuenta las veces que cada una de las palabras se repiten. Como resultado final, se tiene una lista de palabras que contiene sus ocurrencias o repeticiones en el documento procesado.
El principal beneficio del paradigma MapReduce es su escalabilidad, permite una ejecución altamente paralelizada y distribuida en una gran cantidad de nodos. Una implementación de código abierto de MapReduce es Hadoop [5].
Herramientas
- NoSQL (Bases de Datos no relacionales). Es una nueva clase de sistemas de administración de bases de datos que difieren fundamentalmente de los sistemas de bases de datos relacionales. Estas bases de datos no requieren tablas con un conjunto fijo de columnas, evitan las UNIONES (JOIN) y generalmente admiten escalamiento horizontal (pueden distribuir los datos en muchos servidores).
Ej.: MongoDB, CouchDB, Cassandra, Redis, BigTable, Hbase, Hypertable, Voldemort, Riak, ZooKeeper
- MapReduce. Es un modelo de programación para dar soporte a la computación paralela sobre grandes colecciones de datos en grupos de computadores / servidores.
Ej.: Hadoop, Hive, Pig, Cascading, Cascalog, mrjob, Caffeine, S4, MapR, Acunu, Flume, Kafka, Azkaban, Oozie, Greenplum
- Almacenamiento para Big Data. Es una arquitectura de computación y almacenamiento que recopila y administra grandes conjuntos de datos y permite el análisis de datos en tiempo real.
Ej.: Amazon S3, HDFS (Hadoop Distributed File System ).
- Servidores para Big Data. Deben ser capaces de manejar una gran cantidad de datos, hasta terabytes o petabytes o más. Si bien no se puede esperar que un solo servidor almacene todos esos datos, es esencial tener en cuenta el almacenamiento de gran volumen y alta velocidad, por lo que los servidores de Big Data tienden a tener unidades almacenamiento de estado sólido y DAS (Direct Attached Storage).
Ej.: EC2, Google App Engine, Elastic, Beanstalk, Heroku
- Procesamiento. Las técnicas de procesamiento de Big Data analizan conjuntos de grandes de datos a escala de terabytes o incluso petabytes. El procesamiento batch (lotes) de datos fuera de línea suele ser a plena potencia y a gran escala. Mientras que el procesamiento de flujo en tiempo real se realiza en la porción más reciente de datos para un perfil de datos específico, con el fin de seleccionar valores atípicos, detecciones de transacciones de fraude, monitoreo de seguridad, etc. Sin embargo, la tarea más difícil es hacer rápidamente (baja latencia) el análisis en tiempo real para un conjunto completo de datos de Big Data. En la práctica significa escanear terabytes (o incluso más) de datos en segundos. Esto solo es posible cuando los datos se procesan con alto grado de paralelismo.
Ej.: R, Yahoo! Pipes, Mechanical Turk, Solr/Lucene, ElasticSearch, Datameer, BigSheets, Tinkerpop
Modelos de Análisis
El valor potencial de Big Data se obtiene solo cuando se aprovecha para apoyar la toma de decisiones. Para permitir una toma de decisiones basada en evidencia, las organizaciones necesitan procesos eficientes para convertir grandes volúmenes de datos en información significativa. Sea que los datos se generen a gran velocidad y/o que provengan de distintas fuentes.
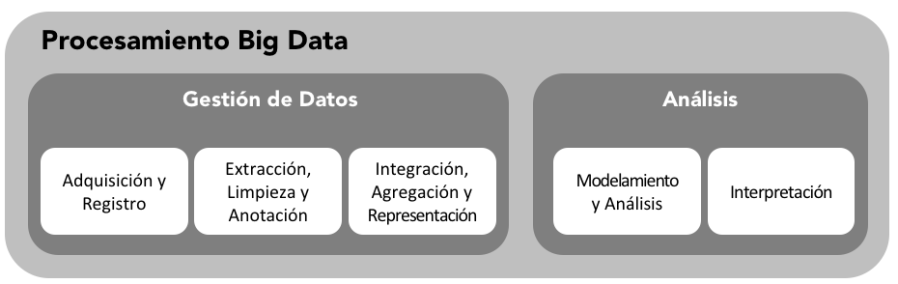
El proceso general de extracción de información del Big Data se puede dividir en cinco etapas [6], que se muestran en la figura de más abajo. Estas cinco etapas forman los dos subprocesos principales: la Gestión de Datos y el Análisis. La Gestión de Datos involucra procesos y tecnologías de soporte para adquirir y almacenar datos, para prepararlos y recuperarlos para su análisis posterior; incluye el LTE (Load, Transform, Extract). Por otro lado, el Análisis –Analytics– es el subproceso que se refiere a las técnicas utilizadas para analizar y adquirir información relevante –inteligencia– a partir de Big Data.
Big Data, ha significado también un cambio de paradigma en términos de enfoque analítico. Eso es un cambio desde el análisis Descriptivo al análisis Predictivo y Prescriptivo [7][8].
Análisis Descriptivo: Visión del Pasado
Responde a las preguntas sobre ¿qué sucedió?. El Análisis Descriptivo o las estadísticas hacen exactamente lo que el nombre implica: «Describen», o resumen los datos en bruto y los convierten en algo interpretable por los humanos. Son análisis que describen el pasado. El pasado se refiere a cualquier momento en que un evento ha ocurrido, ya sea hace un minuto o hace un año. Los análisis descriptivos son útiles porque nos permiten aprender de los comportamientos pasados y comprender cómo pueden influir en los resultados futuros.
La gran mayoría de las estadísticas que utilizamos entran en esta categoría. (Piense en la aritmética básica como sumas, promedios, porcentajes de cambio). Por lo general, los datos subyacentes son un recuento o agregado de una columna de datos filtrada a la que se aplica matemática básica. Para todos los propósitos prácticos, hay un número infinito de estas estadísticas. Las estadísticas descriptivas son útiles para mostrar cosas como stock total en inventario, pesos promedio gastados por cliente y variación de las ventas de año en año. Los ejemplos más comunes de análisis descriptivos son informes que proporcionan información histórica sobre la producción, finanzas, operaciones, ventas, finanzas, contabilidad, inventario y clientes de la compañía.
Se usa el Análisis Descriptivo cuando se necesita comprender a nivel agregado lo que está sucediendo en una empresa y cuándo desea resumir y describir los diferentes aspectos del negocio.
Análisis Predictivo: Comprender el Futuro
Apunta a responder ¿qué podría pasar?. Esto es más difícil e implica extrapolar tendencias y patrones al futuro. El Análisis Predictivo comprende una variedad de técnicas que predicen resultados futuros basados en datos históricos y actuales. En la práctica, el análisis predictivo puede aplicarse a casi todas las disciplinas, desde predecir el fallo de los motores a reacción basados en el flujo de datos de varios miles de sensores hasta predecir los próximos movimientos de los clientes en función de lo que compran, cuándo compran e incluso qué dicen en las redes sociales.
En esencia, el análisis predictivo busca descubrir patrones y capturar relaciones en los datos. Las técnicas de análisis predictivo se subdividen en dos grupos. Algunas técnicas, como los promedios móviles, intentan descubrir los patrones históricos en las variables de resultado y extrapolarlas al futuro. Otros, como la regresión lineal, intentan capturar las interdependencias entre las variables de resultado y las variables explicativas, y explotarlas para hacer predicciones. Con base en la metodología subyacente, las técnicas también se pueden clasificar en dos grupos: técnicas de regresión y técnicas de aprendizaje automático (por ejemplo, redes neuronales).
Se usa el Análisis Predictivo cada vez que se necesita saber algo sobre el futuro, o completar la información que no se tiene.
Análisis Prescriptivo: Aconsejar Sobre Posibles Situaciones
Intenta responder, ¿cómo lo manejo? ¿cómo lo hago?. El relativamente nuevo campo del Análisis Prescriptivo permite a los usuarios prescribir / recetar una serie de posibles acciones diferentes y guiarlos hacia una solución. En pocas palabras, estos análisis tienen que ver con proporcionar asesoramiento. El Análisis Prescriptivo intenta cuantificar el efecto de las decisiones futuras para asesorar sobre los posibles resultados antes de que las decisiones se tomen en realidad.
En el mejor de los casos, el Análisis Prescriptivo predice no solo lo que sucederá, sino también por qué ocurrirá al proporcionar recomendaciones sobre acciones que aprovecharán las predicciones.
Estos análisis van más allá del análisis Predictivo y Descriptivo ya que son capaces de recomendar uno o más cursos de acción posibles. Básicamente, predicen futuros múltiples y permiten a las empresas evaluar una serie de posibles resultados en función de sus acciones. El Análisis Prescriptivo usa una combinación de técnicas y herramientas tales como reglas comerciales, algoritmos, aprendizaje automático y procedimientos de modelado computacional. Estas técnicas se aplican contra la entrada de muchos conjuntos de datos diferentes, incluidos datos históricos y transaccionales, feeds de datos en tiempo real y Big Data.
Los Análisis Prescriptivos son relativamente complejos de administrar, y la mayoría de las empresas aún no los utilizan en su actividad diaria. Cuando se implementan correctamente, pueden tener un gran impacto en la forma en que las empresas toman decisiones y en sus resultados. Las compañías más grandes están utilizando con éxito el Análisis Prescriptivo para optimizar la producción, la programación / planificación y el inventario en la cadena de suministro, para asegurarse de que están entregando los productos correctos en el momento correcto y optimizando la experiencia del cliente.
Se usa el Análisis Prescriptivo cada vez que se necesita brindarles a los usuarios consejos sobre qué medidas tomar.
Análisis Según la Naturaleza de los Datos
Hoy en día se disponen de enormes cantidades de datos provenientes de distintos orígenes, que a su vez corresponden a alguna naturaleza específica, como ser: textos, audios, videos, de redes sociales, IoT, etc. Por otra parte; estos datos pueden estar estructurados o no. Estos conjuntos de datos son sobre los que Big Data opera, utilizando distintos tipos de análisis, algunos de los cuales se describen a continuación.
Análisis de Texto
El análisis de texto (minería de textos) se refiere a técnicas que extraen información de datos textuales. Los registros de redes sociales, correos electrónicos, blogs, foros en línea, respuestas a encuestas, documentos corporativos, noticias y registros del centro de llamadas son ejemplos de datos textuales en poder de las organizaciones. El análisis de texto incluye: análisis estadístico, lingüística computacional y aprendizaje automático. El análisis de texto permite a las empresas convertir grandes volúmenes de texto generado por humanos en resúmenes significativos, que respaldan la toma de decisiones basada en la evidencia. Por ejemplo, el análisis de texto se puede utilizar para predecir el mercado de valores en función de la información extraída de las noticias financieras.
Análisis de Audio
El análisis de audio analiza y extrae información de datos de audio no estructurados. Cuando se aplica al lenguaje humano hablado, el audio análisis también se conoce como análisis de voz. Dado que estas técnicas se han aplicado principalmente al audio hablado, los términos analítica de audio y análisis de voz se usan indistintamente. Actualmente, los centros de atención al cliente y la atención médica son las principales áreas de aplicación de análisis de audio.
Los centros de llamadas utilizan análisis de audio para un análisis eficiente de miles o incluso millones de horas de llamadas grabadas. Estas técnicas ayudan a mejorar la experiencia del cliente, evaluar el desempeño del agente, mejorar las tasas de rotación de ventas, controlar el cumplimiento de diferentes políticas (por ejemplo, políticas de privacidad y seguridad), obtener información sobre el comportamiento del cliente e identificar problemas de productos o servicios, entre muchas otras tareas.
Análisis de video
El análisis de video, también conocido como análisis de contenido de video (VCA – Video Content Analysis), involucra una variedad de técnicas para monitorear, analizar y extraer información significativa de las grabaciones de video. Ya se han desarrollado varias técnicas para procesar videos en tiempo real y pregrabados. La creciente prevalencia de cámaras de televisión de circuito cerrado (CCTV) y la gran popularidad de los sitios web de intercambio de videos son los dos principales contribuyentes al crecimiento del análisis de video computarizado. Sin embargo, un desafío clave es el gran tamaño de los datos de video. Para poner esto en perspectiva, un segundo de un video de alta definición, en términos de tamaño, es equivalente a más de 2.000 páginas de texto y YouTube señala que se cargan sobre 100 horas de video por minuto.
Los datos generados por las cámaras de CCTV en los puntos de venta se pueden extraer para la inteligencia de negocios. El marketing y la gestión de operaciones son las principales áreas de aplicación. Por ejemplo, los algoritmos inteligentes pueden recopilar información demográfica sobre los clientes, como la edad, el género y la etnia. Del mismo modo, los minoristas –Retail– pueden contar la cantidad de clientes, medir el tiempo que permanecen en la tienda, detectar sus patrones de movimiento, medir su tiempo de permanencia en diferentes áreas y monitorear las colas en tiempo real.
Análisis de Redes Sociales
El análisis de redes sociales se refiere al análisis de datos estructurados y no estructurados de los canales de redes sociales. Las redes sociales son un término amplio que abarca una variedad de plataformas en línea que permiten a los usuarios crear e intercambiar contenido. Las redes sociales se pueden clasificar en los siguientes tipos: redes sociales (p. Ej., Facebook y LinkedIn), blogs (p. Ej., Blogger y WordPress), microblogs (p. Ej., Twitter y Tumblr), noticias sociales (p. Ej., Digg y Reddit). marcadores sociales (p. ej., Delicious y StumbleUpon), medios compartidos (p. ej., Instagram y YouTube), wikis (p. ej., Wikipedia y Wikihow), sitios de preguntas y respuestas (p. ej., Yahoo Answers y Ask.com) por ejemplo, Yelp, TripAdvisor) Además, muchas aplicaciones móviles, como Find My Friend, proporcionan una plataforma para las interacciones sociales y, por lo tanto, sirven como canales de redes sociales.
Aunque la investigación en las redes sociales se remonta a principios de la década de 1920, el análisis de redes sociales es un campo emergente que ha surgido después del advenimiento de la Web 2.0 a principios de la década de 2000. La característica clave del análisis moderno de redes sociales es su naturaleza centrada en los datos. La investigación sobre análisis de redes sociales se extiende a través de varias disciplinas, que incluyen psicología, sociología, antropología, informática, matemáticas, física y economía. El marketing ha sido la aplicación principal del análisis de redes sociales en los últimos años.
Usos
A título ilustrativo a continuación se incluyen diez usos comunes hoy en día de Big Data [9], en el entendido que existen muchas más aplicaciones de esta tecnología.
- Entender y orientar a los clientes. Esta es una de las áreas más grandes y más publicitadas de uso de Big Data. Aquí, los grandes datos se usan para comprender mejor a los clientes, sus comportamientos y preferencias.
- Comprender y optimizar los procesos de negocios. Big Data se usan cada vez más para optimizar los procesos de negocios. Los minoristas –retail– pueden optimizar sus existencias en función de las predicciones generadas a partir de los datos de las redes sociales, las tendencias de búsqueda web y las previsiones meteorológicas.
- Evaluación y optimización del rendimiento individual. Big Data no solo es para empresas y gobiernos, sino también para todos nosotros individualmente. Ahora podemos beneficiarnos de los datos generados a partir de dispositivos portátiles como relojes inteligentes o brazaletes inteligentes.
- Mejorar la salud personal y la salud pública. El poder de computación del análisis de Big Data permite decodificar cadenas de ADN completas en minutos y permitirá encontrar nuevas curas y comprender y predecir mejor los patrones de las enfermedades.
- Mejorar el rendimiento deportivo. La mayoría de los deportes de élite ahora han adoptado el análisis de Big Data. Por ejemplo, la herramienta IBM SlamTracker para torneos de tenis; el uso del análisis de video que rastrean el desempeño de cada jugador en un juego de fútbol o béisbol, y la tecnología de sensores en equipos deportivos como pelotas de baloncesto o palos de golf permite obtener retroalimentación (a través de teléfonos inteligentes y servidores en la nube) sobre el juego de cada quién y cómo mejorarlo.
- Mejorar la ciencia y la investigación. La ciencia y la investigación están siendo transformadas por las nuevas posibilidades que aporta Big Data. Por ejemplo, el CERN, el laboratorio de física nuclear con su Gran Colisionador de Hadrones, el acelerador de partículas más grande y poderoso del mundo utiliza esta tecnología.
- Optimización del rendimiento de máquinas y dispositivos. El análisis de Big Data ayuda a las máquinas y dispositivos a ser más inteligentes y autónomos. Por ejemplo, las herramientas de Big Data se utilizan para operar el auto sin chofer de Google.
- Mejorar la seguridad y la aplicación de la ley. Big Data se aplica en gran medida para mejorar la seguridad y permitir la aplicación de la ley. Así se tiene que la Agencia de Seguridad Nacional (NSA, por sus siglas en inglés) de los EE. UU. utiliza el análisis de Big Data para frustrar complots terroristas. Otros usan técnicas de Big Data para detectar y prevenir ataques cibernéticos.
- Mejorar y optimizar ciudades y países. Big data se usa para mejorar muchos aspectos de las ciudades y países. Por ejemplo, permite a las ciudades optimizar los flujos de tráfico en función de la información del tráfico en tiempo real, así como de las redes sociales y los datos meteorológicos.
- Comercio financiero (Bolsa de Comercio). El comercio de alta frecuencia (HFT) es un área donde los macrodatos encuentran un gran uso hoy en día. Aquí, los algoritmos de Big Data se utilizan para tomar decisiones comerciales. Hoy en día, la mayoría de las operaciones con acciones se lleva a cabo a través de algoritmos de datos que toman cada vez más en cuenta las señales de redes sociales y sitios web de noticias para tomar, comprar y vender tomando decisiones en fracciones de segundo.
Roles
El personal calificado para Big Data es un problema crítico. Para el año 2018, Estados Unidos solo podría enfrentar una escasez de 140,000 a 190,000 personas que tengan grandes habilidades analíticas, según el McKinsey Global Institute [10]. Guardando las proporciones me parece que en nuestros países tenemos un problema parecido.
Básicamente tres son los roles indispensables para poder desarrollar una operación Big Data. Para el Proceso de Gestión de Datos se requieren: Ingeniero Datos / Big Data Specialist, que recopila y estructura los datos en el repositorio de Big Data. Y para el Proceso de Análisis de Datos se necesitan al Científico Datos / Data Scientist, que establece la arquitectura y modelos y al Analista Big Data / Data Analyst, que implementa, testea y opera los modelos aprobados por el Negocio.
Las definiciones siguientes son a modo ilustrativo, ya que los conocimientos, experiencia y habilidades dependen de las necesidades propias de cada empresa.
Ingeniero Datos
Es un miembro crítico de su equipo de Big Data porque están dedicados al proceso fundamental de capturar, almacenar y procesar los datos. El Ingeniero de Datos comprenderá y organizará los datos, además los seleccionará y buscará maneras de llevarlo a las personas adecuadas (analistas de negocios). Implementa la arquitectura general que ayuda a analizar y procesar los datos de la manera en que la organización los necesita, y se asegurará que esos sistemas se optimicen de manera efectiva [11]. Participa en el subproceso Gestión de Datos.
Analista Big Data
Es quién implementa los modelos diseñados por el Científico de Datos, trabaja con datos ya debidamente generados y organizados por el Ingeniero de Datos y realiza análisis en ese conjunto de datos. El Analista Big Data ayuda al Científico de Datos a realizar los trabajos necesarios para obtener los resultados de los modelos. Participa en el subproceso Análisis de Datos.
Un Analista Big Data necesita tener habilidades similares a las de un Científico de Datos. Debe ser capaz de apoyar al negocio y la administración con análisis claros y perspicaces sobre los datos disponibles. Esto incluye habilidades de minería de datos (incluyendo auditoría de datos, agregación, validación y reconciliación), técnicas avanzadas de modelado, prueba y creación y explicación de resultados en informes claros y concisos.
Científico Datos – Data Scientist
Es quien utiliza los datos incorporados a la arquitectura Big Data. Estas personas ayudan a crear modelos de aprendizaje automático que su equipo luego implementará –Analista Big Data. La comprensión de los Científicos de Datos de los principios del análisis estadístico les permitirá obtener información de los datos que ayudará a responder preguntas empresariales importantes y generará valiosos conocimientos.
Los Científicos de Datos combinan estadísticas, matemáticas, programación, resolución de problemas, las formas para la captura de datos, la capacidad de ver las cosas de manera diferente para encontrar patrones. Participan en el subproceso Análisis de Datos.
Unidades
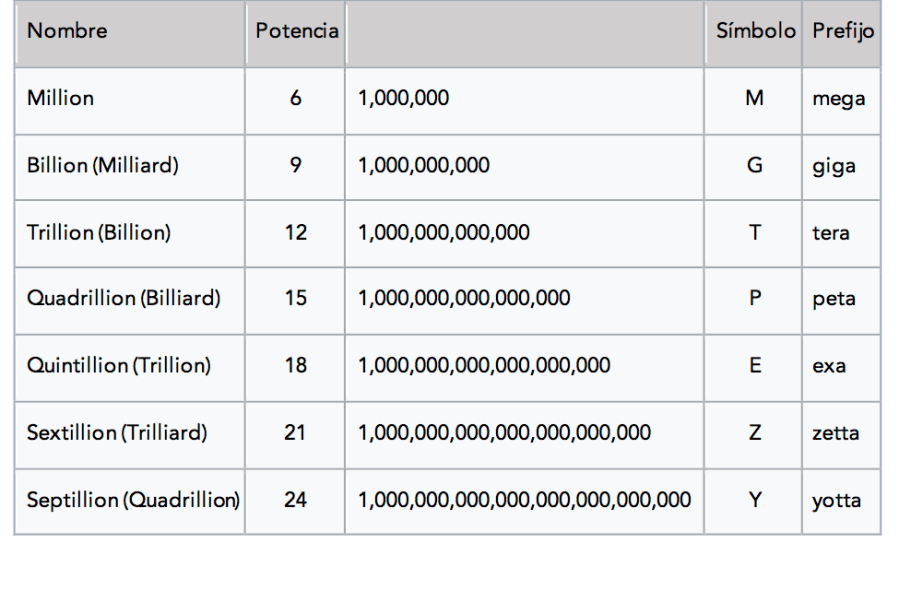
La tabla siguiente muestra las denominaciones que se le asigna a las potencias de diez [12], que se usan para dimensionar la cantidad de Bytes; por ejemplo: Peta(Bytes), Giga(Bytes). En la columna Nombre se muestra la denominación de la escala larga entre paréntesis[ii].
Referencias
[1] https://www.simplilearn.com/data-science-vs-big-data-vs-data-analytics-article
[2] https://www.researchgate.net/publication/291229189_Big_Data_Understanding_Big_Data
[3] https://en.wikipedia.org/wiki/Big_data
[4] https://en.wikipedia.org/wiki/ACID
[7] https://www.ntnu.no/iie/fag/big/lessons/lesson2.pdf
[8] https://halobi.com/blog/descriptive-predictive-and-prescriptive-analytics-explained/
[9] https://www.bernardmarr.com/default.asp?contentID=1076
[10] https://hbr.org/2013/07/five-roles-you-need-on-your-bi
[11] https://www.datameer.com/company/datameer-blog/big-data-job-descriptions-hire-recruit-team/
[12] https://en.wikipedia.org/wiki/Power_of_10
Todas las referencias están verificadas mediante consultas realizadas el 25 de Febrero de 2018.
[i] 1 Zettabytes = Un Trillardio o 1021 bytes (1.000.000.000.000.000.000.000)
[ii] Los países donde la escala larga se utiliza actualmente incluyen la mayoría de los países de Europa continental y la mayoría de los países de habla francesa, hispanohablantes y de habla portuguesa, excepto Brasil. La escala corta ahora se usa en la mayoría de los países de habla inglesa y árabe, en Brasil, en la antigua Unión Soviética y en varios otros países.
